K4A supported research projects in African natural language processing now available in study
K4A has been instrumental in contributing to the roadmap for African language technologies. The new study investigates the motivations, focus and challenges faced by stakeholders at the core of the NLP ecosystem in an African context.
By identifying and interviewing core stakeholders in the NLP process a number of recommendations are proposed for use by policymakers, AI researchers, and other relevant stakeholders in aid of the betterment of the development of language content and language technology.
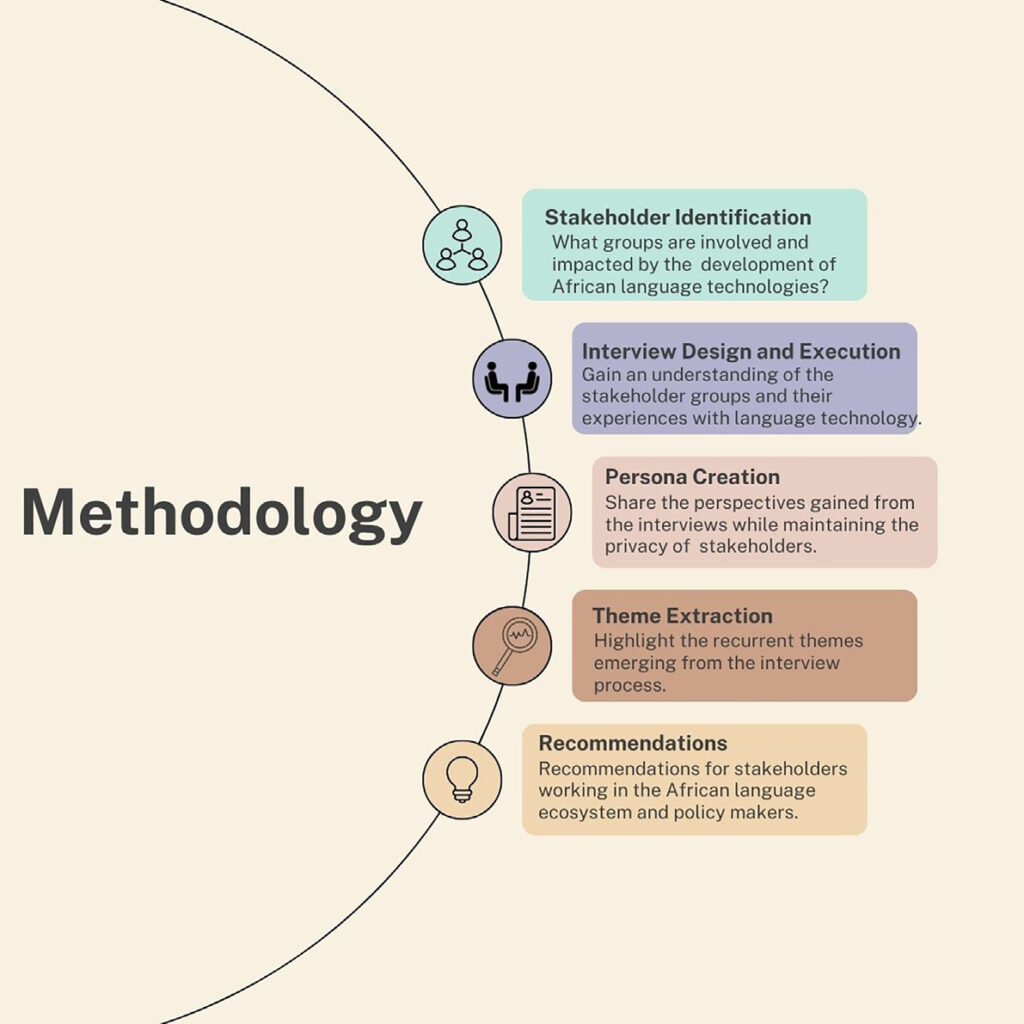
The K4A grantees have put forward the following recommendations for stakeholders working in the African language ecosystem:
- Language acquisition of Indigenous African languages, primarily by Africans, should be better supported, and technology is a means to do this, as has been the case for many other non-African languages.
- Basic tooling to support content creation on digital platforms, such as digital dictionaries, thesauruses, keyboards supporting diacritics where relevant, and spell checkers that recognize African names and places without error, should be prioritized.
- Language tools and processes for content moderation and to catch and control the spread of misinformation online in Indigenous African languages should be developed and actively used.
- Language careers and the professional opportunities available, particularly as pertains to Indigenous African languages, should be made more visible to students earlier in their education so as to generate greater interest in these fields in tertiary education.
- AI language tools that augment human activities as opposed to tools seeking to replace them should be the intentional design choice, especially given the current dearth of tooling and data for African languages.
- Computational linguistics components should be introduced into the educational curricula of disciplines adjacent to and working with language, e.g., linguistics and journalism, with an emphasis on the role they can play in the development of ethical and inclusive AI so as to encourage a pipeline of cross-discipline stakeholders working to build language technology.
- Professional training opportunities to enable multilingual individuals to venture into language careers should be increased.
- The study of contemporary use of language in Africa should be emphasized, given increasing urbanization and the multicultural nature of the continent.
- Funding for dataset creation and annotation, both of which can be time-consuming and expensive tasks, should be increased.
- African language policies, particularly those pertaining to education and provision of government services, should be better implemented with the aid of emerging language tools and technologies.
- Digital licensing and funding should be made suitable to support legal cases against non-African corporations who use open African data.
- An ‘‘ethical data curation toolkit,’’ which is informed by information scientists, data privacy experts, and machine learning bias experts, would empower dataset curators with the knowledge and skills to perform informed data curation.
- The toolkit should be accompanied by a workshop in which practical training and discussions can take place.