

Building a database for Yoruba language in Africa
Cracking the Language Barrier for a Multilingual Africa
Description
This dataset is part of a 3-4 month Fellowship Program within the AI4D – African Language Program, which was conceptualized as part of a roadmap to work towards better integration of African languages on digital platforms, in aid of lowering the barrier of entry for African participation in the digital economy.
This particular dataset is being developed through a process covering a variety of languages and NLP tasks, in particular Machine Translation of Yoruba.
Language profile: Yoruba
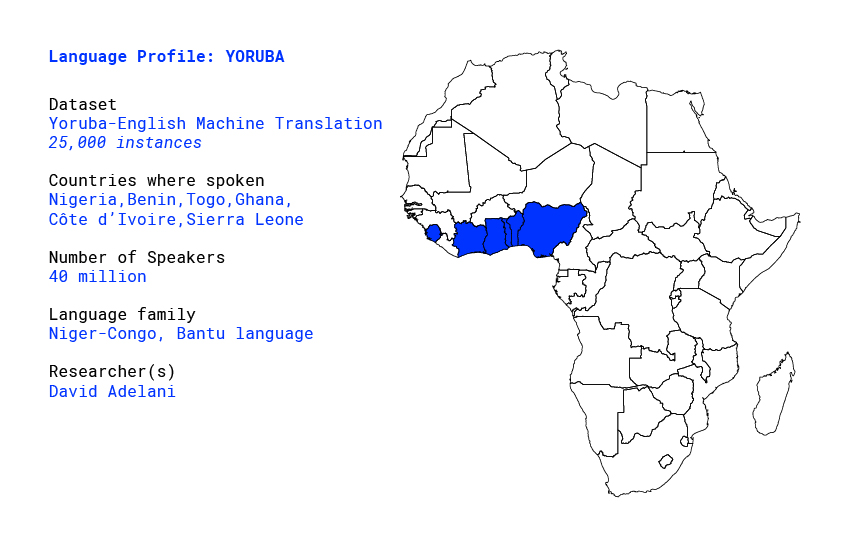
Overview
The Yorùbá language is the third most spoken language in Africa, and is native to the south-western Nigeria and the Republic of Benin in West Africa (as shown in Figure 1). It is one of the national languages in Nigeria, Benin and Togo, and it is also spoken in other countries like Ghana, Côte d’Ivoire, Sierra Leone, Cuba, Brazil and by a significant Yorùbá diaspora population in the US and United Kingdom mostly from the Nigerian ancestry. The language belongs to the Niger-Congo family, and is spoken by over 40 million native speakers [1].
Yorùbá has several dialects but the written language has been standardized by the 1974 Joint Consultative Committee on Education [2], it has 25 letters without the Latin characters (c, q, v, x and z) and with additional characters (ẹ , gb, ṣ , and ọ). There are 18 consonants (b, d, f, g, gb, j, k, l, m, n, p, r, s, s., t, w y), and 7 oral vowels (a, e, ẹ , i, o, ọ , u). Yorùbá is a tonal language with three tones: low, middle and high.
These tones are represented by the grave (“\”), optional macron (“- ”) and acute (“/”) accents respectively. These tones are applied on vowels and syllabic nasals, but the mid tone is usually ignored in writings. The tones are represented in written texts along with a modified Latin alphabet. A few alphabets have underdots (i.e. “ẹ ”, “ọ ”, and “ṣ”), we refer to the tonal marks and underdots as diacritics. It is important to note that tone information is needed for correct pronunciation and to have the meaning of a word [2, 3].
As noted in [4], most of the Yorùbá texts found in websites or public domain repositories either use the correct Yorùbá orthography or replace diacriticized characters with un-diacriticized ones.
Oftentimes, articles written online including news articles1 like BBC and VON ignore diacritics. Ignoring diacritics makes it difficult to identify or pronounce words except they are in a context. For example, owó (money), ọwọ̀ (broom), òwò (business), ọ̀wọ̀ (honour), ọwọ́ (hand), and ọ̀wọ́ (group) will be mapped to owo without diacritics.
Existing work
Due to the problem with the diacritics in Yorùbá language, it has greatly reduced the amount of available parallel texts that can be used for many NLP tasks like machine translation. This has led to research on automatically applying diacritics to Yorùbá texts [5, 6], but the problem has not been completely solved. We will divide the existing work on Yorùbá language into four categories:
Automatic Diacritics Application
The main idea for the automatic diacritic application (ADA) model is to predict the correct diacritics of a word based on the context it appears. We can make use of a sequence-to-sequence deep learning model like Long Short Term Memory networks (LSTM) [7] to achieve this task.
The task is similar to a machine translation task where we need to translate from a source language to a target language, ADA takes a source text that is non-diacriticized (e.g “bi o tile je pe egbeegberun ti pada sile”) and outputs target texts with diacritics (e.g. “bí ó tilẹ̀ jẹ́ pé ẹgbẹẹgbẹ̀rún ti padà síléé”). The first attempt of applying deep learning models to Yorùbá ADA was by Iroro Orife [5].
They proposed a soft-attention seq2seq model to automatically apply diacritics to Yorùbá texts, their model was trained on the Yorùbá bible, Lagos-NWU speech corpus and some language blogs. However, the model does not generalize to other domains like dialog conversation and news domain because the majority of the texts are from the Bible. Orife et al [6] recently addressed the issue of domain-mismatch by gathering texts from various sources like conversation interviews, short stories and proverbs, books, and JW300 Yorùbá texts but they evaluated the performance of the model on the news domain (i.e Global Voices articles) to measure domain generalization.
Word Embeddings
Word embeddings are the primary features used for many downstream NLP tasks. Facebook released FastText [8] word embeddings for over 294 languages 2 but the quality of the embeddings are not very good. Recently, Alabi et. al [9] showed that Facebook’s FastText embeddings for Yorùbá gives a lower performance in word similarity tasks, which indicates that they would not work well for many downstream NLP tasks. They released a better quality FastText embeddings and contextualized BERT [10] embeddings obtained by fine-tuning multi-lingual BERT embeddings.
Datasets for Supervised Learning Tasks
Yorùbá, like many other low-resourced languages, does not have many supervised learning datasets such as named entity recognition (NER), text classification and parallel sentences for machine translation. Alabi et al. [9] created a small NER dataset with 26K tokens. Through the support of AI4D 3 and Zindi Africa 4, we have created parallel English-Yorùbá dataset for machine translation and news title classification dataset for Yorùbá from articles crawled from BBC Yorùbá 5. The summary of the AI4D dataset creation competition is in [11].
Machine Translation
Commercial machine translation models like Google Translate 6 exist for Yorùbá to other languages but the quality is not very good because of the diacritics problem and the small amount of data available to train a good neural machine translation (NMT) model. JW300[12] based on Jehovah Witness publications is another popular dataset for training NMT models for low-resource African languages, it has over 10 million tokens of Yorùbá texts. However, the NMT models trained on JW300, do not generalize to other non-religious domains. There is a need to create more multi-domain parallel datasets for Yorùbá language.
Researcher Profile: David Adelani
David Ifeoluwa Adelani is a doctoral student in computer science at Spoken Language Systems Group, Saarland Informatics Campus, Saarland University, Saarbrücken, Germany. His current research focuses on the security and privacy of users’ information in dialog systems and online social interactions.
He is also actively involved in the development of natural language processing datasets and tools for low-resource languages, with special focus on African languages. He has published a few papers in top Web technology, language and speech conferences including The Web Conference, LREC, and Interspeech.
During his graduate studies, he conducted research on social computing at the Max Planck Institute of Software Systems, Germany and on fake review detection at the National Institute of Informatics, Tokyo, Japan. He holds an MSc in Computer Science from the African University and Science and Technology, Abuja, Nigeria and a BSc in Computer Science from the University of Agriculture, Abeokuta, Nigeria.
Partners

Disclaimer
The designations employed and the presentation of material on these map do not imply the expression of any opinion whatsoever on the part of the Secretariat of the United Nations concerning the legal status of any country, territory, city or any area or of its authorities, or concerning the delimitation of its frontiers or boundaries. Final boundary between the Republic of Sudan and the Republic of South Sudan has not yet been determined. Final status of the Abyei area is not yet determined.