African languages are richer for 20 more language datasets
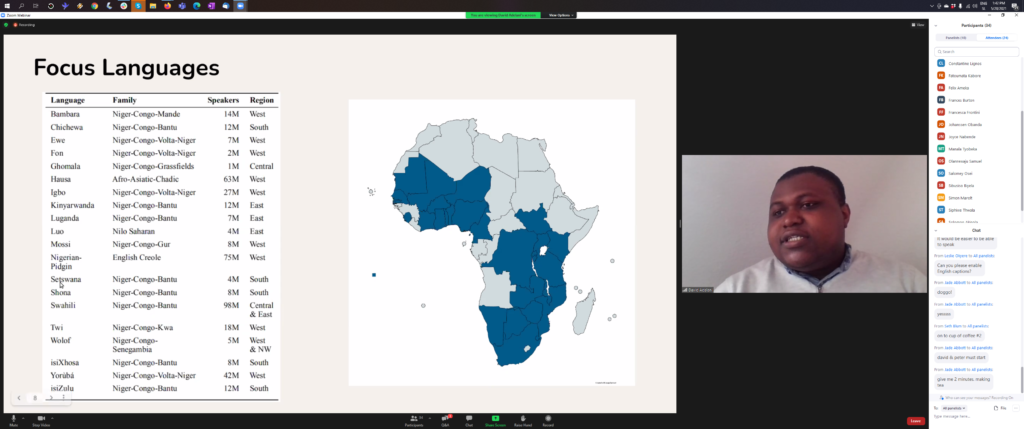
We are very happy to announce that one of our Lacuna funded projects titled Named Entity Recognition and parts of Speech Datasets for African Languages has been successfully finished. At the start of our work, none of the languages associated with this project had a manually prepared NER dataset. Also, only a very small subset of languages in South Africa, and Yoruba, Naija, Wolof, and Bambara had Part-of-speech (POS) datasets. This project has therefore provided the first carefully prepared NER and POS datasets for 20 African languages. The project initially achieved new parallel texts (up to 8000 parallel sentences) for at least 8 low-resourced languages. The parallel texts are a very valuable resource for bilingual NLP applications. The results will be uploaded to the Masakhane Github repository.