AI4D blog series: Extracting meta-data from Malawi Court Judgments
We have set the task to develop semi-automatic methods for extracting key information from criminal cases issued by courts in Malawi. Our body of court judgments came partly from the MalawiLii platform and partly from the High Court Library in Blantyre, Malawi. We focussed our first analysis on cases between 2010 – 2019.

Here is an example of a case for which a PDF is available on MalawiLii. Here is an example of a case for which only a scanned image of a pdf is available. We used OCR for more than 90% of data to extract the text for our corpus (see below a description of our corpus).
Please open these files to familiarise yourself with the content of a court criminal judgment. What kind of information we want to extract? For each case we wanted:
- Name of the Case
- Number of the Case
- Year in which the case was filled
- Year in which the judgment was given, Court which issued the judgment
- Names of Judges
- Names of parties involved (appellants and respondents, but you can take this further and extract names of principal witnesses, and names of victims)
- References to other Cases
- References to Laws/Statues and Codes, and,
- Legal keywords which can help us classify the cases according to the ICCS classification.
This project has taught us so much about working with text, preparing data for a corpus, exchange formats for the corpus data, analysing the corpus using lexical tools, and machine learning algorithms for annotating and extracting information from legal text.
Along the way we experimented also with batch OCR processing and different annotation formats such as IOB tagging[1], and the XML TEI[2] standard for sharing and storing the corpus data, but also with the view of using these annotations in sequence-labelling algorithms.
Each has advantages and disadvantages, the IOB tagging does not allow nesting (or multiple labelling for the same element), while an XML notation would allow this but it is more challenging to use in algorithms. We also learned how to build a corpus, and experimented with existing lexical tools for analysing this corpus and comparing it to other legal corpora.
We learned how to use POS annotations and contextual regular expressions to extract some of our annotations for laws and case citations and we generated more than 3000 different annotations. Another interesting thing we learned is that preparing annotated training data is not easy, for example, most algorithms require training examples to be of the same size and the training set needs to be a good representation of the data.
We also experimented with the classification algorithms and topics detection using skitlearn, spacy, weka and mathlab. The hardest task was to prepare the data in the right format and to anticipate how this data will lead to the outputs we saw. We felt that time spent in organising and annotating well is not lost but will result in gains in the second stage of the project when we focus on algorithms.
Most algorithms split the text into tokens, and for us, multi-word tokens (or sequences) are those we want to find and annotate. This means a focus on sequence-labelling algorithms. The added complications which are peculiar to legal text is that most of our key terms belong logically to more than one label, and the context of a term can span multiple chunks (e.g., sentences).
When using LDA (Latent Dirichlet Association) to detect topics in our judgments, it became clear to us that one needs to use a somehow ‘sumarised’ version in which we collapse sequences of words into their annotations (this is because LDA uses term frequency-based measure of keyword relevance, whereas in our text the most relevant words may appear much less frequently than others).
Our work has highlighted to us the benefits and importance of multi-disciplinary cooperation. Legal text has its peculiarities and complexities so having an expert lawyer in the team really helped!
Finding references to laws and cases is made slightly more complicated because of the variety in which these references may appear or because of the use of “hereinafter”. Legal text makes use of “hereinafter”[3], e.g., Mwase Banda (“hereinafter” referred to as the deceased). But this can also happen for references to laws or cases as the following example shows:
Section 346 (3) of the Criminal Procedure and Evidence Code Cap 8:01 (hereinafter called “the Code”) which Wesbon J was faced with in the case of DPP V Shire Trading CO. Ltd (supra) is different from the wording of Section 346 (3) of the Code as it stands now.
Compare extracting the reference to law from “Section 151(1) of the Criminal Procedure and Evidence Code” to extracting from “Our own Criminal Procedure and Evidence Code lends support to this practice in Sections 128(d) and (f)”. We have identified a reasonably large number of different references to laws and cases used in our text! The situation is very similar for case citations. Consider the following variants:
- Republic v Shautti , Confirmation case No. 175 of 1975 (unreported)
- Republic v Phiri [ 1997] 2 MLR 68
- Republic v Francis Kotamu , High Court PR Confirmation case no. 180 of 2012 ( unreported )
- Woolmington v DPP [1935] A.C. 462
- Chiwaya v Republic 4 ALR Mal. 64
- Republic v Hara 16 (2) MLR 725
- Republic v Bitoni Allan and Latifi Faiti
Something for you to Do Practically! To play with some annotations and appreciate the diversity in formats, and at the same time the huge savings that a semi-automatic annotation can bring, we have set up a doccano platform for you: you log in here using the user guest and password Gu3st#20.
Annotating with keywords for the purposes of the ICCS classification proved to be even harder. The International Classification of Crime for Statistical Purposes (ICCS)[4] and it is a classification of crimes as defined in the national legislations and comes on several levels each with varying degrees of the specification. We considered mainly the Level 1 and we wanted to classify our judgments according to the 11 types in Level 1 as shown in the Table.
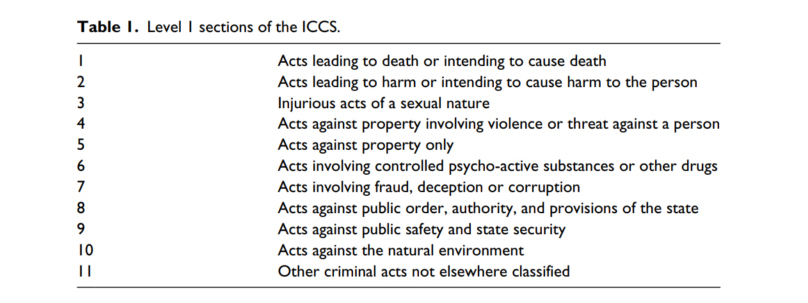
We discovered that this task of classification according to Level 1 requires a lot of work and it is of a significant complexity (and the complexities only grow if we would consider the sublevels of the ICCS). First, the legal expert of our team manually classified all criminal cases of 2019 according to Level 1 ICCS and worked on a correspondence between the Penal Code and the ICCS classification. This is excellent.
We are in the process of extending this to mapping other Malawi laws, codes and statutes that are relevant to criminal cases into the ICCS. This in itself is a whole project on its own for the legal profession and requires processing a lot of text and making ‘parallel correspondences’! Such national correspondence tables are still work in progress in most countries and to our knowledge, our work is the first of such work for Malawi.
Looking at Level 1 of the ICCS meant we were kept very busy. Our research centred on hard and important questions. How to represent our text so that it can be processed efficiently? What kind of data labels are most useful for the ICCS classification? What type of annotations to use (IOB or an xml-based)? What algorithms to employ (Hidden Markov Models or Recurrent Neural Networks or Long Short Term Memory)? But most importantly, we focussed on how to prepare our annotated data to be used with these algorithms?
We need to be mindful that this is a fine classification because we have to distinguish between texts that are quite similar. For example, if we wanted to classify whether a judgment by the type of law it falls under, say whether it is either civil or criminal case, this would have been slightly easier because the keywords/vocabulary used in civil cases would be quite different than that used in criminal cases.
We want to distinguish between types of crimes, and the language used in our judgments is very similar. Within our data set there is the level of difficulty, e.g., theft and murder cases may be easier to differentiate, that is Type 1 and 7 from the table above, than, say, to differentiate between types 1 and 2.
We have the added complication that most text representation models which define the relevance of a keyword as given by its frequency (whether that is TF or TF-IDF) but in our text, a word may appear only once and still be the most significant word for the purpose of our classification. For example, a keyword that distinguishes between type 1 and type 2 murders is “malice aforethought” and this may only occur once in the text of the judgment.
To help with this situation, one can extract first the structure of the judgment and focus only on the part that deals with the sentence of the judge. Indeed, there is research that focuses only on extracting various segments of a judgment.
This may work in many cases because usually the sentence is summarised in one paragraph. But it does not work for all cases. This is so especially when the case history is long, the crime committed has several facets, or the case has several counts, e.g., the murder victim is an albino or a disabled person.
In such situations one needs a combined strategy which uses: (1) An good set of annotated text with meta-data described above; (2) the mapping of the Penal Code/ Laws/Statues relevant to the ICCS; (3) collocations of words/ or a thesaurus and (4) concordances to help us detect clusters and extract relevant portions of the judgments; (5) employing sequence modelling algorithms, e.g., HMM, recurrent neural networks, for annotation and classification.
In the first part of the project, we focussed on the tasks (1) – (4) and experimented to some extent with (5). What we wanted is to find a representation of our text based on all the information at (1) – (4) and attempt to use that in the algorithms we employ.
We have created a training set of over 2500 annotations for references to sections of the law and over 1000 annotations for references to other cases. We are still preparing these so that they are representative of the corpus and are good examples.
And finally but most importantly, while working on this AI4D project, it has brought me in contact with very clever people, whom I would have not otherwise met. We appreciate the support and guidance of the AI4D team!
[1] https://en.wikipedia.org/wiki/Inside%E2%80%93outside%E2%80%93beginning_(tagging)
[2] http://fedora.clarin-d.uni-saarland.de/teaching/Corpus_Linguistics/Tutorial_XML.html
[3] Hereinafter is a term that is used to refer to the subject already mentioned in the remaining part of a legal document. Hereinafter can also mean from this point on in the document.
[4] United Nations Economic Commission for Europe. Conference of European Statisticians. Report of the UNODC/UNECE Task Force on Crime Classification to the Conference of European Statisticians. 2011. Available: www.unodc.org/documents/data-andanalysis/statistics/crime/Report_crime_classification_2012.pdf>
Reposted within the project “Network of Excellence in Artificial Intelligence for Development (AI4D) in sub-Saharan Africa” #UnitedNations #artificialintelligence #SDG #UNESCO #videolectures #AI4DNetwork #AI4Dev #AI4D