Work partially funded by K4A has won the inaugural 2021 Wikimedia Foundation Research Award of the Year with the paper “Participatory Research for Low-resourced Machine Translation: A Case Study in African Languages” and the Masakhane Community
This paper and the Masakhane community have attempted to fundamentally change how we approach the challenge of “low-resourced languages” in Africa via a set of projects funded by K4A, with the support of UNESCO, IDRC, and GIZ. The research describes a novel approach for participatory research around machine translation for African languages. The authors show how this approach can overcome the challenges these languages face to join the Web and some of the technologies other languages benefit from today.
The work of the authors and the community is an inspiring example of work towards Knowledge Equity, one of the two main pillars of the 2030 Wikimedia Movement Strategy. “As a social movement, we will focus our efforts on the knowledge and communities that have been left out by structures of power and privilege. We will welcome people from every background to build strong and diverse communities. We will break down the social, political, and technical barriers preventing people from accessing and contributing to free knowledge.”
We cannot think of a better or more inspiring example of a project we have been involved in the last couple of years.
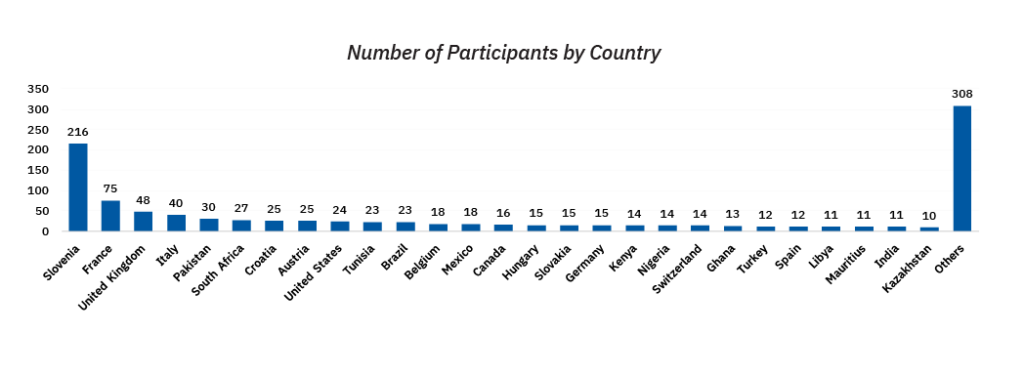
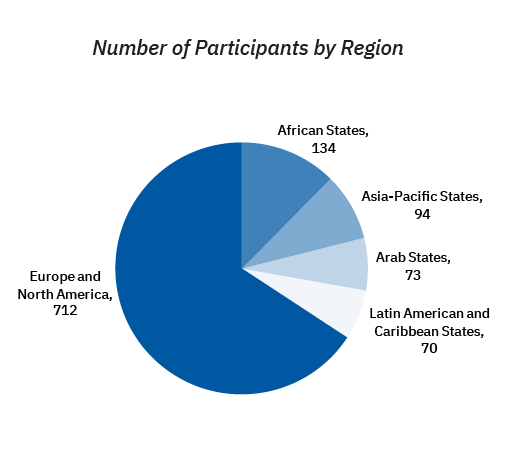
On March 29 and 30 2021, the IRCAI launch event took place. 1083 registered participants from 123 countries attended and were addressed by esteemed speakers on the first day of the event. Participants came from all geographical regions of United Nations: African, Asian-Pacific, Eastern European, Latin American and Caribbean and Western European states. Non-registered participants were also invited to watch the event via live streaming on YouTube. The launch was created with input from 33 active speakers and panelists.
In his speech, the President of the Republic of Slovenia, Mr. Borut Pahor, emphasized that the establishment of IRCAI in Ljubljana is a great recognition for Slovenian researchers and the Jožef Stefan Institute who have been working on artificial intelligence in Slovenia for several decades. According to President Pahor, artificial intelligence is a tool for a better life and offers great opportunities “for progress, for more accessible and efficient public services, quality education and better access to information, and helps us fight climate change, introduce new forms of mobility and use energy more efficiently.”
The Director-General of the United Nations Educational, Scientific and Cultural Organization (UNESCO), Ms Audrey Azoulay, who attended the event live from Paris, regretted that she could not be there live as originally planned and welcomed IRCAI to the UNESCO family. “IRCAI has become a space that directs academic and human resources to research topics within the mandate of UNESCO, which, as you know, includes education, culture, science and information,” adding that despite the large number of UNESCO centers, none yet deals with artificial intelligence. “Thanks to IRCAI, we now have the support of an entire team that is directing its diverse skills to ensure that artificial intelligence is used in a way that serves the common good. We are fortunate to have an ally like this to help make our ambitions reality,” she added, explaining the important role IRCAI played in drafting the UNESCO Recommendation on Ethical Artificial Intelligence and personally thanking the team for their efforts in leading the regional consultation on the draft recommendation. “We have already had a glimpse of the potential of this partnership. This inauguration is therefore very promising,” she concluded.
The Minister of Education, Science and Sport of Slovenia,Prof Simona Kustec stressed the importance of cooperation in creating opportunities to address current challenges, including through artificial intelligence, and called on all participants to work together. The Minister of Public Administration of Slovenia, Mr Boštjan Koritnik stressed that “Slovenia aims for a high quality and ethical use of artificial intelligence that citizens can trust” and emphasized that artificial intelligence will be one of the main priorities during the Slovenian EU Presidency.
The development of artificial intelligence in Slovenia was also highlighted by prof. Boštjan Zalar, Director of the Jožef Stefan Institute, who stressed that the Institute has a 40-year history in the development of artificial intelligence, over 70 major projects in various departments of the Institute and that in his opinion IRCAI can further strengthen these achievements.
Support for IRCAI was also expressed by the representative of European Commission with which IRCAI has many strategic synergies. Anthony Whelan , Digital Policy Adviser from the cabinet of European Commission President Ursula von der Leyen noted, “It is indeed a nice coincidence that the Slovenian Presidency is preparing to work with such an excellent asset at its doorstep, and we hope that this will also serve as a flagship for international efforts.“
The sequence of events leading to the establishment of IRCAI and the results of the Center’s work so far were presented by its Director, Prof. John Shawe-Taylor. “IRCAI has already established active cooperation with a wide range of international organizations, which it intends to further strengthen and expand,” he said in his speech. Among other things, he called for active participation through projects listed on the Center’s website.
On the first day, a panel discussion, which included several speakers from African countries, focused on building a global artificial intelligence community. The second day of the event focused on presentations of the results of IRCAI activities, opportunities for collaboration, and the use of artificial intelligence tools to support the achievement of Sustainable Development Goals. Presentations were given by IRCAI Program Committee representatives Aidan O’Sullivan, Colin de La Higuera, Catherine Holloway and Delmiro Fernandez-Reyes.
Analyzes of 6 Regional Consultations on UNESCO recommendation on AIethics and IRCAI ethics andregulatory approaches were presented alongside panel discussions on the issues of the need for policy action on AI. IRCAI Funding and Innovation Program: Social Impact Bonds, AI policies around the world and AI Global Observatory were also presented by IRCAImember organizations Daniel Miodovnik, Mark Minevich and Marko Grobelnik respectively. The presentations included 5 reports co-authored by IRCAI representatives: Artificial Intelligence in Sub-Saharan Africa, Artificial Intelligence Needs Assessment Survey in Africa, UNESCO Ethics of AI Recommendation Regional Consultations, Opinion Series Reports: UNESCO Ethics of AI Recommendation Regional Consultations, Responsible Artificial Intelligence in Sub-Saharan Africa and Powering Inclusion: Artificial Intelligence and Assistive Technology.
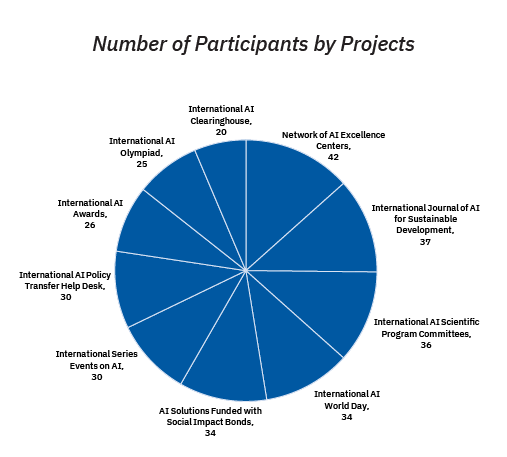
A call for collaboration has also been launched to join IRCAI, which is actively working on 10 projects to be implemented by 2021. These are all designed to scale and deploy AI to achieve the Global Challenges that the Center has set out to achieve. IRCAI is seeking partnerships with, International Organizations, governments, companies, NGOs, universities, research institutes, AI consortia and government agencies around the world to implement these projects.
The aim of our project is to investigate the technological feasibility of deploying Unmanned Ground Vehicles for automated wildlife patrol, as well as performing a preliminary analysis of other metadata collected from officials at a national park in Kenya. To this end, we seek to collect and publish a dataset of driving data across national park trails in Kenya, the first of its kind, and use deep learning to predict steering wheel angle when driving on these trails.
Khushal Brahmbhatt, Deep Learning and Computer Vision researcher, Autonomous Vehicles
Ronald Ojino Co-researcher (Autonomous Driving Research)/ PhD student (University of Dar es Salaam)/Lecturer – Cooperative University of Kenya
Setting up the data acquisition system
The data collection required a vehicle mounted with a camera to be driven across national park trails while recording the trail video as well as key driving signals such as steering wheel angle, speed and brake and accelerator pedal positions. We began design, installation and configuration of the data collection system in November and December 2019.
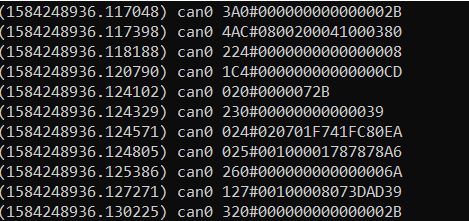
The first idea was to procure and attach sensors to the vehicle to obtain these driving signals. But upon further research, it was discovered that most of these driving signals can be read from the CAN bus which is exposed on the OBD-II (On-Board Diagnostics) port on most vehicles manufactured after 2008.
This information however is grouped and encoded within different parameter ids, and it requires reverse engineering to identify each of these driving parameters which is significantly time consuming, an activity that would take months by itself.
Furthermore, not all of the driving signals would be exposed on the CAN bus. The parameters exposed on the bus vary between vehicle manufacturers and models, and so does the encoding. After failing to understand the data read from the CAN bus of our personal vehicles, we decided to find a vehicle model which had already been reverse-engineered.
We were able to identify [1] and procure a Toyota Prius 2012 for the data collection, from which we could read the steering wheel angle, steering wheel torque, vehicle speed, individual wheel speeds and brake and accelerator pedal positions. We used a Raspberry Pi 3 microcomputer with the PiCan hat to read and log the driving signals.
Encoded driving data seen on the vehicle’s CAN bus
In order to create the dataset for training and testing the learning algorithm, each data sample would have to contain a video frame matched to the corresponding driving signals at that instance. That means all the video frames, as well as the driving signals, have to be timestamped.
The driving signals are automatically timestamped during logging on the Raspberry Pi, but most cameras don’t timestamp the individual frames. Further, the internal clock of the camera would not be in sync with that of the RPi’s, and would cause the video frames and driving signals to also be out of sync when creating the data samples.
That means a camera that could interface to the computer as a webcam would be needed, so each frame can be read and timestamped before being written to the video file. Driving on rough national park trails would also induce a lot of vibrations and require a camera with good stabilization. These were some of the challenges in selecting a camera for recording the driving video.
We settled on the Apeman A80 action camera which has gyro stabilization, HD video recording and can also function as a webcam. OpenCV was used to read and record timestamped video to the computer.
Initially, we tried to connect the camera to the Raspberry Pi itself. But the RPi is a low-powered microcomputer. There was significant lag in recording and could not write the video higher than a frame rate of 8fps. We therefore decided to use a laptop which could comfortably record HD
video at 30fps to connect to the camera, and the RPi for only logging the driving signals from the vehicle’s CAN bus.
This however presented a different challenge of being limited by the laptop battery. While the RPi can be charged using a portable power bank or directly from the car’s charging port, the laptop cannot. That meant significantly shorter data collection runs. We could only drive around continuously for 2 hours before we had to return to charge the laptop which took another 2 hours.
This forced revising down our overall data collection projections from 50 hours to 20 hours, of which 25 hours which was to be on the national park trails was revised down to 10 hours, and the other 10 hours on a mixture of tarmac roads and other rural dirt roads.
There was also extensive testing of different video encoding methods to determine the best filesize versus quality tradeoff, as well as data collection code optimization to ensure minimum lag during the data logging.
Data collection
We began the data collection in January 2020 on tarmac and rural dirt roads. The idea behind this was to train the algorithm on a simpler dataset and then use transfer learning for better faster results on the national park trails. The data was collected at various times of the day: early in the morning, noon and late in the evening in order to get a varied dataset in different lighting conditions.
While we were able to smoothly collect the data on tarmac roads, driving over the rural dirt roads proved impossible as they were marked with potholes. Not only was it challenging to drive a low-body vehicle over the rough terrain, but the constant maneuvers made to go around the potholes meant that most of that data would be unusable as it would present a different challenge altogether in training.
The challenge of driving a low-body vehicle on dirt roads also limited our choices of national parks, as we had to carefully select ones with smooth driving trails. Our plan to collect data from the Maasai Mara National Reserve had to be abandoned due to the bad road conditions there, and we opted to collect data from Nairobi National Park (8 hrs) and Ruma National Park (2.5 hrs) instead. Even these however were not without their setbacks involving a flat tire and bumper damage.
Sample video frames from Nairobi National Park (left, center) and Ruma National Park (right)
Sample video frames from Nairobi National Park (left, center) and Ruma National Park (right)
Sample video frames from Nairobi National Park (left, center) and Ruma National Park (right)
Another challenge faced in the parks was internet connectivity. While a stable internet connection was not needed for the data collection which was done offline, a connection to the internet was needed when starting up the Raspberry Pi to allow it to initialize the correct datetime value.
This is because the RPi microcomputer does not have an internal clock. That means unless it has a connection to the internet, it will resume the clock from the last saved time before it was shut down, hence ending up showing the wrong time. That resulted in incorrect timestamps on the logged driving data that could not be matched to the video timestamps.
This was observed while analyzing the driving data logs from one of the runs at Ruma National Park. Luckily, internet connectivity was regained towards the end of the run and the rest of the timestamps could be calculated correctly using the message baud rates.
Other minor issues faced in obtaining good quality data involved keeping the windshield clean while driving on dusty park trails where one is not allowed to alight from the vehicle, and securely mounting the camera inside the vehicle while driving over rough terrain.
Dataset preparation and Training
A significant portion of the data collected included driving around potholes, overtaking, stopping, U-turns etc. which would not be useful for predicting the steering wheel angle within the scope of this study. All these segments had to be visually identified and removed before
preparing the dataset.
Initially, we proposed to use a simple Convolutional Neural Network (CNN) model for training as in [2], where the steering wheel angle is predicted independently on each video frame as the input. However, the steering angle is also largely dependent on the speed of the vehicle. Driving
is also a stateful process, where the current steering wheel angle is also dependent on the previous wheel position.
We therefore investigated the use of a more sophisticated temporal CNN model as in [3] using recurrent units such as LSTM and Conv-LSTM that could give more promising results. The above model however is very computationally expensive and would require a cluster of very expensive GPUs and still take days to train.
Using this model proved impossible to achieve within the given timeline and budget. We therefore decided to continue with our initial proposal using a static CNN model [2].
Currently we are in the process of building the dataset and learning model for the project. We are also working on preparing a preliminary analysis on the feasibility of automated wildlife patrol [4] based on other metadata collected from park officials.
We are grateful for the immense support that we always get from our mentor Billy Okal who in spite of his busy schedule, gets the time to set up calls whenever we need to consult and always comes up with great ideas that address most of our concerns.
References
[1] C. Miller and C. Valasek, Adventures in Automotive Networks and Control Units, IOActive
Inc., 2014, pp. 92-97.
[2] M. Bojarski et al., End to end learning for self-driving cars, 2016, arXiv:1604.07316.
[3] L. Chi and Y. Mu, Deep steering: Learning end-to-end driving model from spatial and
temporal visual cues, 2017, arXiv:1708.03798.
[4] L. Aksoy et al., Operational Feasibility Study of Autonomous Vehicles, Turkey International
Logistics and Supply Chain Congress, 2016.
Amelia Taylor, University of Malawi | UNIMA · Information Technology and Computing
Here is an example of a case for which a PDF is available on MalawiLii. Here is an example of a case for which only a scanned image of a pdf is available. We used OCR for more than 90% of data to extract the text for our corpus (see below a description of our corpus).
Please open these files to familiarise yourself with the content of a court criminal judgment. What kind of information we want to extract? For each case we wanted:
Name of the Case
Number of the Case
Year in which the case was filled
Year in which the judgment was given, Court which issued the judgment
Names of Judges
Names of parties involved (appellants and respondents, but you can take this further and extract names of principal witnesses, and names of victims)
References to other Cases
Referencesto Laws/Statues and Codes, and,
Legal keywords which can help us classify the cases according to the ICCS classification.
This project has taught us so much about working with text, preparing data for a corpus, exchange formats for the corpus data, analysing the corpus using lexical tools, and machine learning algorithms for annotating and extracting information from legal text.
Along the way we experimented also with batch OCR processing and different annotation formats such as IOB tagging[1], and the XML TEI[2] standard for sharing and storing the corpus data, but also with the view of using these annotations in sequence-labelling algorithms.
Each has advantages and disadvantages, the IOB tagging does not allow nesting (or multiple labelling for the same element), while an XML notation would allow this but it is more challenging to use in algorithms. We also learned how to build a corpus, and experimented with existing lexical tools for analysing this corpus and comparing it to other legal corpora.
We learned how to use POS annotations and contextual regular expressions to extract some of our annotations for laws and case citations and we generated more than 3000 different annotations. Another interesting thing we learned is that preparing annotated training data is not easy, for example, most algorithms require training examples to be of the same size and the training set needs to be a good representation of the data.
We also experimented with the classification algorithms and topics detection using skitlearn, spacy, weka and mathlab. The hardest task was to prepare the data in the right format and to anticipate how this data will lead to the outputs we saw. We felt that time spent in organising and annotating well is not lost but will result in gains in the second stage of the project when we focus on algorithms.
Most algorithms split the text into tokens, and for us, multi-word tokens (or sequences) are those we want to find and annotate. This means a focus on sequence-labelling algorithms. The added complications which are peculiar to legal text is that most of our key terms belong logically to more than one label, and the context of a term can span multiple chunks (e.g., sentences).
When using LDA (Latent Dirichlet Association) to detect topics in our judgments, it became clear to us that one needs to use a somehow ‘sumarised’ version in which we collapse sequences of words into their annotations (this is because LDA uses term frequency-based measure of keyword relevance, whereas in our text the most relevant words may appear much less frequently than others).
Our work has highlighted to us the benefits and importance of multi-disciplinary cooperation. Legal text has its peculiarities and complexities so having an expert lawyer in the team really helped!
Finding references to laws and cases is made slightly more complicated because of the variety in which these references may appear or because of the use of “hereinafter”. Legal text makes use of “hereinafter”[3], e.g., Mwase Banda (“hereinafter” referred to as the deceased). But this can also happen for references to laws or cases as the following example shows:
Section 346 (3) of the Criminal Procedure and Evidence Code Cap 8:01 (hereinafter called “the Code”) which Wesbon J was faced with in the case of DPP V Shire Trading CO. Ltd (supra) is different from the wording of Section 346 (3) of the Code as it stands now.
Compare extracting the reference to law from “Section 151(1) of the Criminal Procedure and Evidence Code” to extracting from “Our own Criminal Procedure and Evidence Code lends support to this practice in Sections 128(d) and (f)”. We have identified a reasonably large number of different references to laws and cases used in our text! The situation is very similar for case citations. Consider the following variants:
Republic v Shautti , Confirmation case No. 175 of 1975 (unreported)
Republic v Phiri [ 1997] 2 MLR 68
Republic v Francis Kotamu , High Court PR Confirmation case no. 180 of 2012 ( unreported )
Woolmington v DPP [1935] A.C. 462
Chiwaya v Republic 4 ALR Mal. 64
Republic v Hara 16 (2) MLR 725
Republic v Bitoni Allan and Latifi Faiti
Something for you to Do Practically! To play with some annotations and appreciate the diversity in formats, and at the same time the huge savings that a semi-automatic annotation can bring, we have set up a doccano platform for you: you log in here using the user guest and password Gu3st#20.
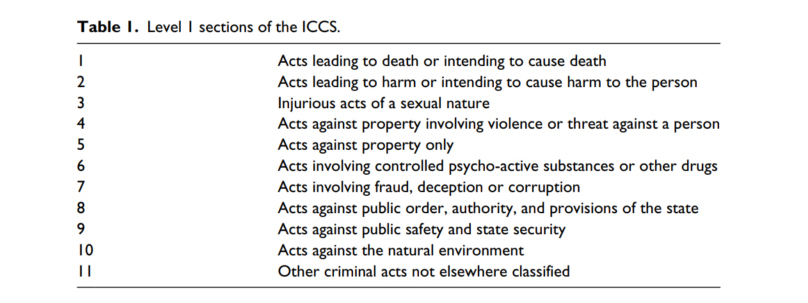
Annotating with keywords for the purposes of the ICCS classification proved to be even harder. The International Classification of Crime for Statistical Purposes (ICCS)[4] and it is a classification of crimes as defined in the national legislations and comes on several levels each with varying degrees of the specification. We considered mainly the Level 1 and we wanted to classify our judgments according to the 11 types in Level 1 as shown in the Table.
Table 1: Level 1 sections of the ICCS
We discovered that this task of classification according to Level 1 requires a lot of work and it is of a significant complexity (and the complexities only grow if we would consider the sublevels of the ICCS). First, the legal expert of our team manually classified all criminal cases of 2019 according to Level 1 ICCS and worked on a correspondence between the Penal Code and the ICCS classification. This is excellent.
We are in the process of extending this to mapping other Malawi laws, codes and statutes that are relevant to criminal cases into the ICCS. This in itself is a whole project on its own for the legal profession and requires processing a lot of text and making ‘parallel correspondences’! Such national correspondence tables are still work in progress in most countries and to our knowledge, our work is the first of such work for Malawi.
Looking at Level 1 of the ICCS meant we were kept very busy. Our research centred on hard and important questions. How to represent our text so that it can be processed efficiently? What kind of data labels are most useful for the ICCS classification? What type of annotations to use (IOB or an xml-based)? What algorithms to employ (Hidden Markov Models or Recurrent Neural Networks or Long Short Term Memory)? But most importantly, we focussed on how to prepare our annotated data to be used with these algorithms?
We need to be mindful that this is a fine classification because we have to distinguish between texts that are quite similar. For example, if we wanted to classify whether a judgment by the type of law it falls under, say whether it is either civil or criminal case, this would have been slightly easier because the keywords/vocabulary used in civil cases would be quite different than that used in criminal cases.
We want to distinguish between types of crimes, and the language used in our judgments is very similar. Within our data set there is the level of difficulty, e.g., theft and murder cases may be easier to differentiate, that is Type 1 and 7 from the table above, than, say, to differentiate between types 1 and 2.
We have the added complication that most text representation models which define the relevance of a keyword as given by its frequency (whether that is TF or TF-IDF) but in our text, a word may appear only once and still be the most significant word for the purpose of our classification. For example, a keyword that distinguishes between type 1 and type 2 murders is “malice aforethought” and this may only occur once in the text of the judgment.
To help with this situation, one can extract first the structure of the judgment and focus only on the part that deals with the sentence of the judge. Indeed, there is research that focuses only on extracting various segments of a judgment.
This may work in many cases because usually the sentence is summarised in one paragraph. But it does not work for all cases. This is so especially when the case history is long, the crime committed has several facets, or the case has several counts, e.g., the murder victim is an albino or a disabled person.
In such situations one needs a combined strategy which uses: (1) An good set of annotated text with meta-data described above; (2) the mapping of the Penal Code/ Laws/Statues relevant to the ICCS; (3) collocations of words/ or a thesaurus and (4) concordances to help us detect clusters and extract relevant portions of the judgments; (5) employing sequence modelling algorithms, e.g., HMM, recurrent neural networks, for annotation and classification.
In the first part of the project, we focussed on the tasks (1) – (4) and experimented to some extent with (5). What we wanted is to find a representation of our text based on all the information at (1) – (4) and attempt to use that in the algorithms we employ.
We have created a training set of over 2500 annotations for references to sections of the law and over 1000 annotations for references to other cases. We are still preparing these so that they are representative of the corpus and are good examples.
And finally but most importantly, while working on this AI4D project, it has brought me in contact with very clever people, whom I would have not otherwise met. We appreciate the support and guidance of the AI4D team!
[3] Hereinafter is a term that is used to refer to the subject already mentioned in the remaining part of a legal document. Hereinafter can also mean from this point on in the document.
[4] United Nations Economic Commission for Europe. Conference of European Statisticians. Report of the UNODC/UNECE Task Force on Crime Classification to the Conference of European Statisticians. 2011. Available: www.unodc.org/documents/data-andanalysis/statistics/crime/Report_crime_classification_2012.pdf>
The projectproposes expanding a framework on categorizing parliamentary bills in Nigeria using Optical Character Recognition (OCR), document embedding and recurrent neural networks to three other countries in Africa: Kenya, Ghana, and South Africa.
His work was accepted at 4th Widening NLP Workshop, Annual Meeting of the Association for Computational Linguistics, ACL 2020.
Knowledge 4 All Foundation partnered with the Deep Learning Indaba to fund research projects across Africa that are collaborative at heart and have a strong development focus.
This Call for Proposals invites individuals, grassroots organizations, initiatives, academic, and civil society institutions to apply for funding for mini-projects.
A mini-project could also be early-stage research around our Grand Challenge of curing leishmaniasis.
In many African countries such as Burkina Faso, people still rely quite often on traditional medicine for both common and uncommon diseases. This is particularly true in rural areas where 71% of the Burkinabe people live. While the research literature acknowledges the pharmacological virtues of some plants, the relevant knowledge is neither sufficiently organized nor widely shared.
Dr Tegawende BIISYANDE, Universite Joseph KI-ZERBO
Faycal OUBDA et Emmanuel SAGNON, Etudiants, Universite Joseph KI-ZERBO
Objectives
The ultimate goal of this project is to build an open and searchable database on medical plants. To that end, the project focuses on (1) collecting a variety of information on such plants from diverse sources, (2) implementing a platform to expose the constructed knowledge, (3) develop context-specific tools to accelerate the accurate identification of plants in the wild.
Team
To successfully carry out the project, we have set up a dedicated team of 10 people:
A research mentor with a background in AI,
A practice mentor with a background in traditional medicine. In this case, the mentor happened to be the director of the promotion of traditional medicine at the Ministry of Health,
A research assistant with a background in Sociology. In this case, the assistant was a student whose responsibility was to help on the collection of ethnobotanical data,
Three computer programmers. In this case, the programmers were computer science students who were tasked to devise and implement the database, the search engine as well as the plant identification tool.
And four investigators to collect data on the virtues of plants
Implementation
(1) Data collection: Work sessions with the practice mentor allowed us to devise an adapted methodology and identify data sources.
The adopted methodology consists of drawing a list of plants based on relevant research literature and leveraging online databases. Then, the team can conduct an ethnobotanical study with traditional medicine practitioners to gather information on the uses of plants for therapeutic purposes. For each plant, we agreed to focus on the following information: Scientific name, Species, Family, Name in three local languages (Moore, Dioula, Fulfulde), Spatial location, Status (endangered or not), medical use (virtues).
The data collection is mainly performed in the two largest cities in the country, namely Ouagadougou and Bobo-Bobo-Dioulasso. In the implementation of the activities, we were surprised by the amount of research that has already been done on medicinal plants, although the data is not sufficiently structured and shared. In addition, we discovered that both at the level of traditional practitioners as well as the state, there are actions being structured for the valorization of traditional medicine. Our project, therefore, reinforces the existing mechanism. In the continuation of the activities, in addition to plants, we plan to create a database of traditional practitioners. In order to be able to reference them more easily in the research works that are carried out.
(2) Platform development: With respect to the platform, we leverage the ElasticSearch engine to build the backend database and search engine.
(3) Plant detector implementation: We also devised a deep learning system to classify plant leaf images for fast identification in the wild. This work required contextualization as we supposed that users will carry mobile phones with little computing power and potentially no data network connectivity. Thus we implemented a neural network model compression algorithm that yielded a classifier with reasonable prediction accuracy and yet was runnable on low-resource devices.
Results
At this stage, while we just crossed the mid-term of the project execution, we can report that a number of milestones have been achieved:
the plant detector has been implemented
the first batch of medicinal plant dataset has been collected
the platform backend architecture has been finalized
We are currently working on a technical infrastructure that organisations can use to issue digital credentials across the EU and beyond. This technical infrastructure could be used by various stakeholders when issuing any type of Digital Credential to learners. The work was presented at the National workshop on micro-credentials and blockchain certification on May 28 in Ljubljana, Slovenia.
Anthony Camillieri, presenting the MicroHE project and the digital credentials landscape in Europe during the “National workshop on micro-credentials and blockchain certification”
National workshop on micro-credentials and blockchain certification for the MicroHE project on May 28, 2020 Ljubljana, Slovenia
National workshop on micro-credentials and blockchain certification for the MicroHE project on May 28, 2020 Ljubljana, Slovenia
Mini-documentary on AI4D Artificial Intelligence 4 Development
We produced a mini-documentary describing the ideas, aspirations, and research potential of our African colleagues in the field of Artificial Intelligence.
The emerging network of machine learning and AI practitioners and researchers undertaking a collaborative roadmap for AI for Development in Africa. The three-day workshop zoomed in on three critical areas of 1) policy and regulations, 2) skills and capacity building and 3) the application of AI in Africa.

/ PhD student (University of Dar es Salaam)/Lecturer – Cooperative University of Kenya")
 and Ruma National Park (right)")
 and Ruma National Park (right)")
 and Ruma National Park (right)")